

RDSのフェイルオーバー時の挙動を理解してみる
突然ですが皆さん、RDS、使ってますか?
こんにちは、クラウドエンジニアの大田です。
先月8月23日に起こった東京リージョンでの大規模障害が起きて久しいですね。
当初単一AZでの影響のみと考えられていた障害でしたが、
RDSやALBでのInternal Server Errorを吐いていたことが分かり、
障害の影響はマルチAZ配置のシステムにも波及していました。
「ウチはマルチAZでフェイルオーバーするから安心!」と思っていたらRDSが停止または自動再起動していた…という方もいらっしゃったのではないでしょうか。
さて、今回のテーマは「RDSのフェイルオーバー時の挙動を理解してみる」です。
主なゴールは、RDSのフェイルオーバー時の挙動を学び、安定稼働のためのヒントを得ていただくことです。
思考停止でとりあえずRDS使っとけ!的な風潮はありますが、やはり内部の動きを正確に理解しておかないと、開発設計時や障害発生時に的確な対応が出来ません。
その中でもサービスの可用性担保において、非常に重要な機能である「フェイルオーバー」について取り上げていきます。
もくじ
1.RDSとは
そもそもRDS?なにそれ美味しいの?という方もいらっしゃると思います。
簡単ではありますが、今回も本記事をお読みいただくための前提知識として解説いたします。
もう知ってるよ!という方は読み飛ばしていただけますと幸いです。
Amazon RDSは Relational Database Service の略で、AWSが提供するRDBMS(Relational Database Management System)のマネージドサービスを指します。
サポートされているデータベースエンジンは Amazon Aurora、PostgreSQL、MySQL、MariaDB、Oracle Database、および Microsoft SQL Server の6種類です。
RDSの何が良いかと言うと「システムのアップグレードやメンテナンスといった管理コストをAWS側に任せることができること」や「可用性やスケーリング、データ冗長化、セキュリティ向上や暗号化のための機能がめちゃくちゃ手軽に実装できること」が代表的なメリットです。
一方デメリットは、全てのデータベースエンジンやバージョンをサポートしているわけではないことやエンジンによっては一部機能に制限があることが挙げられます。
代表的な機能は下記の通りです。
- ワークロードに応じたインスタンスタイプの選択
- スループットに応じたストレージの選択
- ストレージの拡張(オンライン拡張、自動拡張も可能)
- 自動または手動バックアップ
- モニタリング
- ログの取得
- メンテナンスウィンドウ(システムメンテナンスの自動実行)
- 削除保護
- リードレプリカ(読み取り処理パフォーマンスの向上)
- フェイルオーバー(障害発生時または再起動時の自動切り替え)
次は、フェイルオーバーについて簡単に解説します。
2.フェイルオーバーとは
こちらも同様に、もう知ってるよ!という方は読み飛ばしていただけますと幸いです。
ざっくりお伝えするとフェイルオーバーとは、「予備も一緒に動かしている(ホットスタンバイ)システムにおいて、メインサーバーに障害が発生したときに自動的に予備サーバーに切り替えてくれる機能」を指します。別名 HA機能 とも呼ばれています。フェイルオーバーの目的は「サービスの継続稼働のための最小ダウンタイムの実現」にあります。
アプリケーションやサービスが停止すると非常に困る!という場面において、障害発生時に稼働可能なサーバーに切り替えることで、サービスを停止することなく最小限のダウンタイムで安定稼働させられるわけですね。
また、フェイルオーバー自体は以下のような要件で使用される場合もあります。
- テスト用の DB インスタンスで障害をシミュレートする
- フェイルオーバー実行後にオペレーションを元の AZ に復元する
基本的なフェイルオーバーの前提条件については、以下の通りです。
【フェイルオーバーの条件】
- スタンバイサーバーがあること
- スタンバイサーバーが起動し続けていること(ホットスタンバイ)
- データの同期がされていること
Amazonフェイルオーバーについて
AWS上のフェイルオーバーのサポートおよび前提条件については、以下の通りです。
【Amazon フェイルオーバーのサポート】
- Oracle、PostgreSQL、MySQL、MariaDB DB インスタンスのマルチ AZ 配置のみ
- SQL Server DB インスタンスでは SQL Server データベースのミラーリング (DBM) が使用される
- Aurora は マルチAZのクラスター構成で Writer / Reader が切り替えられる
【Amazon フェイルオーバーの条件】
- Amazon RDS インスタンスがマルチ AZ 用に構成されていること
※マルチ AZ 配置の場合は、AZから別AZへのフェイルオーバーの強制実行も可能
- 自動フェイルオーバーの実行条件
- AZ障害(機能停止)
- DBインスタンス のエラー
- DBインスタンス のタイプ変更
- DBインスタンス のストレージ不良
- DB インスタンスのオペレーティングシステムでソフトウェアのパッチ適用中
- DB インスタンスの手動フェイルオーバーが [Reboot with failover] を使用して開始された
本記事の検証では「DB インスタンスの手動フェイルオーバーを実施( [Reboot with failover] を使用して開始)する」ことで自動フェイルオーバーを発生させます。また、今回はRDSとAuroraに分けて検証します。RDSの中でもAuroraはフェイルオーバー時に特徴的な動きをするので、挙動の違いをあわせて理解しましょう。
3.実際にやってみた
検証では、Aurora と RDS for MySQL をそれぞれ使用します。
まずは挙動の分かりやすいAuroraからまいりましょう。
Aurora
■AuroraのDBインスタンスを起動する
マルチAZ配置を確認
クラスターエンドポイントを確認
クラスター内の書き込みインスタンス(Writer)と読み込みインスタンス(Reader)のDB識別子を確認

■Aurora フェイルオーバー実行
今回はWriterをフェイルオーバーさせ、インスタンスが切り替わるかを検証
書き込みインスタンス(Writer)を選択
アクション→[フェイルオーバー]を選択
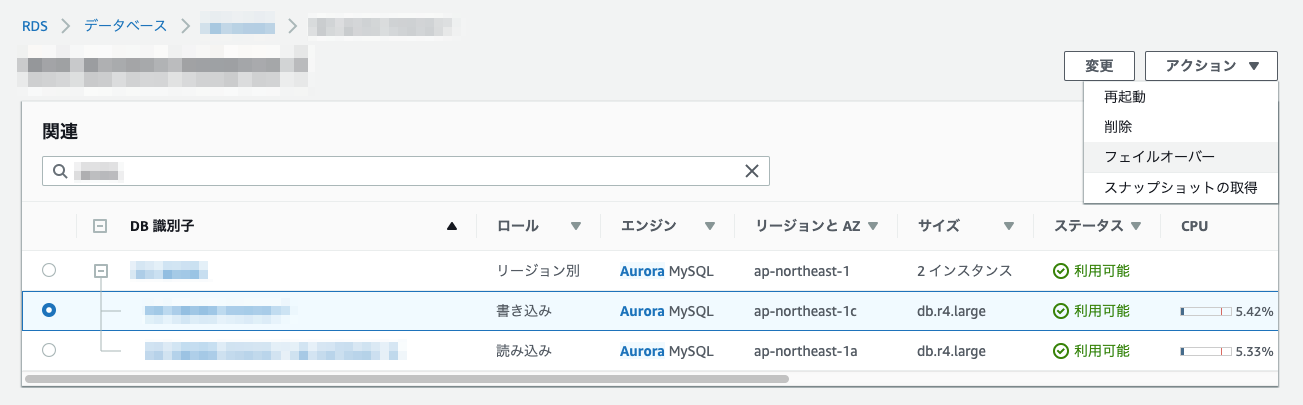
フェイルオーバーを実行

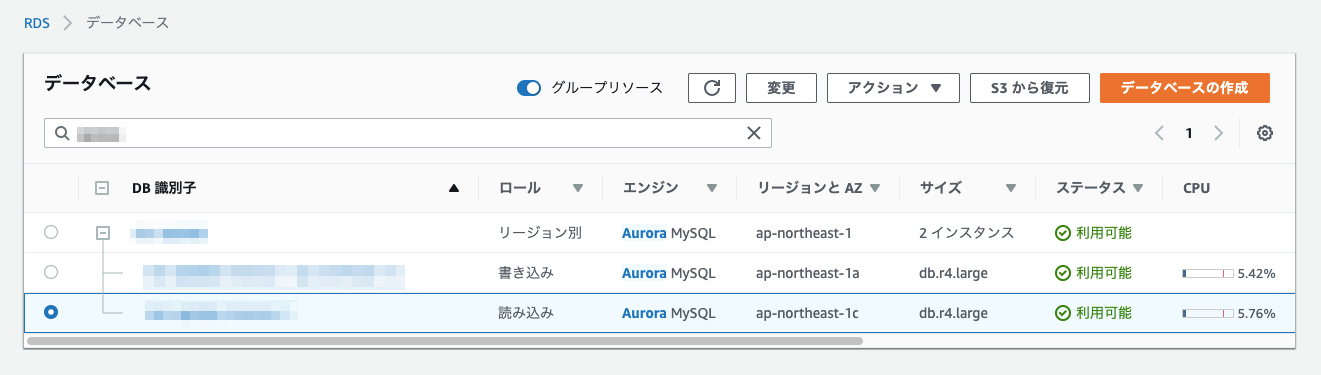
WriterだったインスタンスがReaderに切り替わり、ReaderだったインスタンスがWriterに切り替わっています。
■フェイルオーバー後のクラスターエンドポイント確認
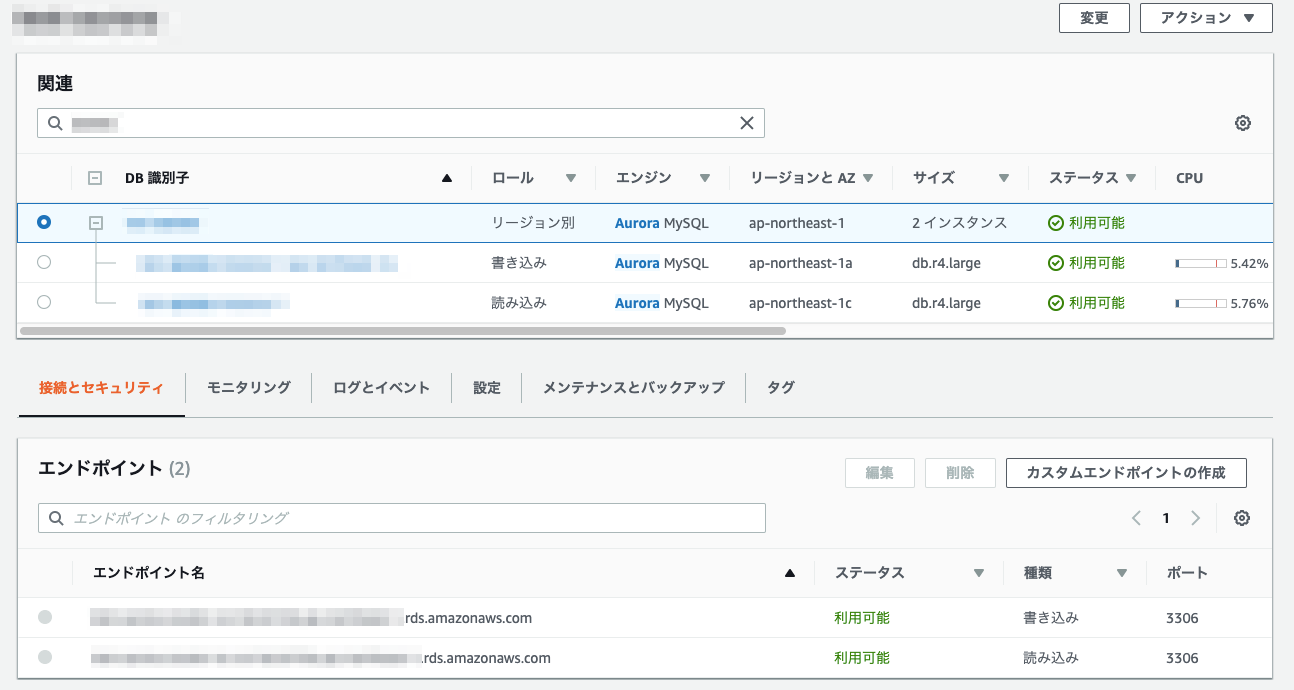
クラスターエンドポイントは変わっていないことが分かります。
■イベントログからフェイルオーバーを確認
イベントログからもフェイルオーバーの実行〜完了を確認できます。

ログを見ると、フェイルオーバーは30秒以内に完了していることが分かります。
続いて、RDS for MySQLでフェイルオーバーを実行してみましょう。
RDS for MySQL
■DBインスタンス作成時に「マルチAZ」を有効にする
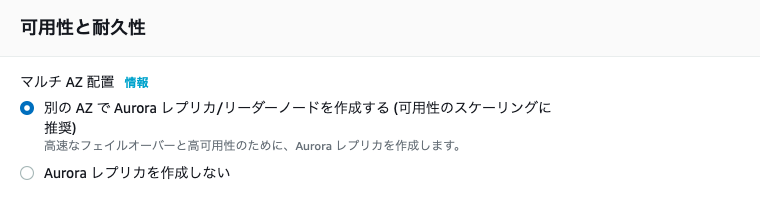
コンソールのDBインスタンスの画面上には「マルチAZ」項目が「はい」と表示されるだけなのですが、内部では スタンバイDBインスタンス が起動しています。
■エンドポイントの確認

■フェイルオーバーの実行
DBインスタンス選択→アクション→[再起動]を選択
「フェイルオーバーし再起動しますか?」にチェック→再起動
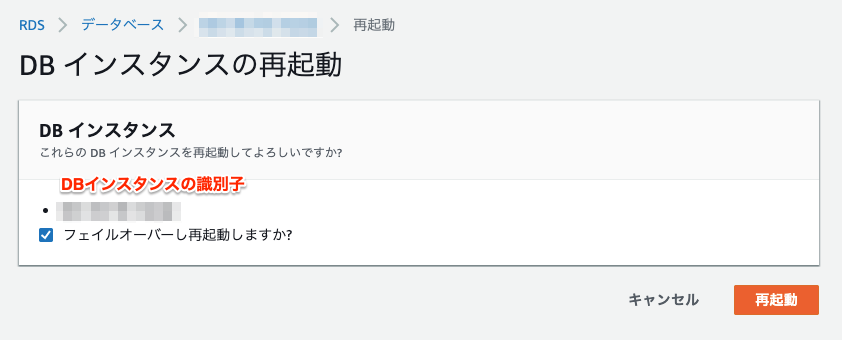
「再起動中」→「利用可能」になったらフェイルオーバー完了
■フェイルオーバー後のエンドポイントを確認
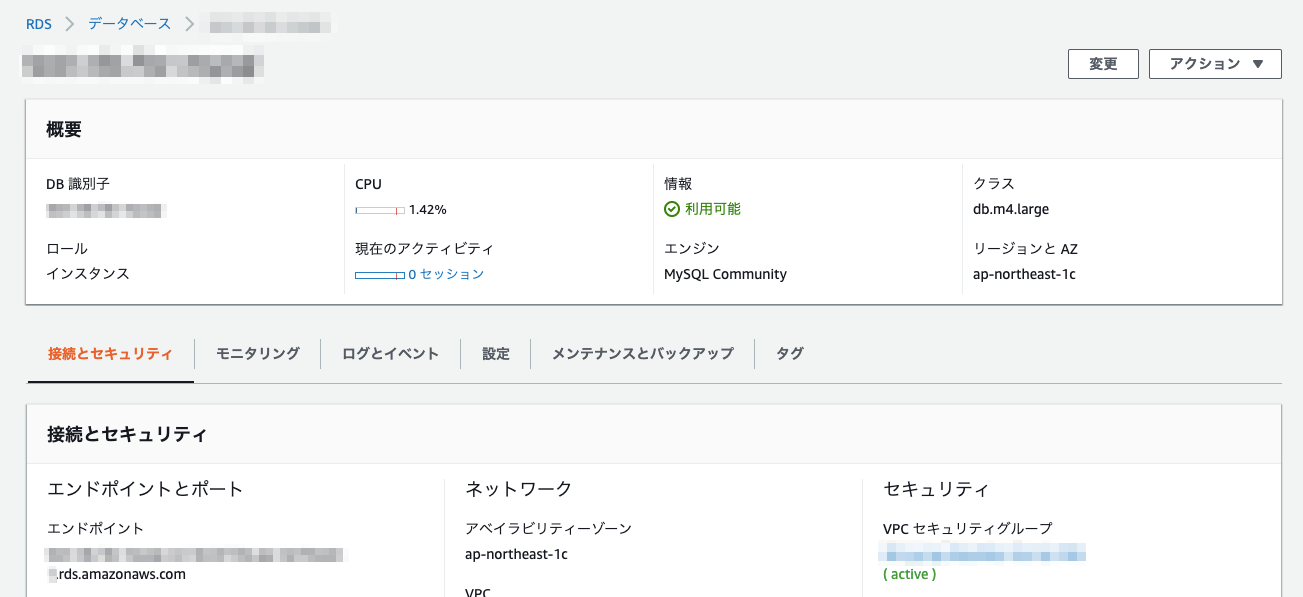
エンドポイントは変わっていませんでした。
しかし、コンソール上ではフェイルオーバーされたかどうかが分かりにくいので、イベントログを確認します。
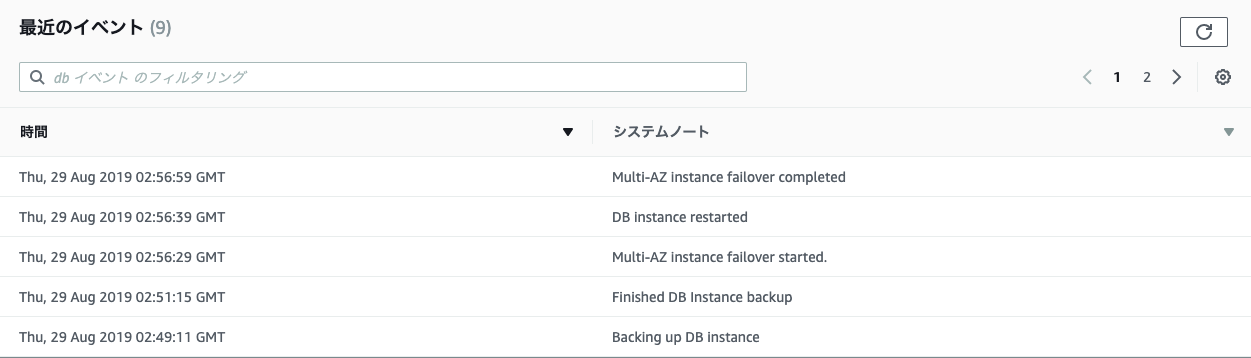
フェイルオーバーが30秒で完了していることが分かります。
4.運用の考察
検証結果を踏まえ、フェイルオーバー時のポイントをまとめてみました。
■フェイルオーバーの挙動
- マルチAZ配置のRDSの場合、フェイルオーバーは内部的に行われる(スタンバイはコンソール上では確認できない)
- Auroraの場合、Writer / Reader を入れ替えることで、フェイルオーバーを実行する
■エンドポイントへの影響
- RDSもAuroraもエンドポイント(Auroraの場合はクラスターエンドポイント)は変わらない
つまり、アプリケーションをエンドポイントと紐付けておけば、フェイルオーバー時の接続先変更を意識する必要がなくなる。
■ダウンタイム
- フェイルオーバー完了までの所要時間は早いと 30秒程度 だった(通常1〜2分程度)。
■その他
- 変更の適用フロー
スケーリングやメンテナンス(システムアップグレード – OS パッチ適用など)時にはスタンバイに変更が適用されてから、自動フェイルオーバーが実行される(下記フロー記載)- スタンバイに変更を適用
- 自動フェイルオーバーの実行
- プライマリに変更を適用
- スタンバイレプリカとリードレプリカは全くの別物
読み取りトラフィック負荷を下げる役割を持つリードレプリカと、今回使用したマルチAZ配置におけるスタンバイレプリカは全くの別物である点にも注意しましょう。スタンバイレプリカは読み取りトラフィックを処理できないため、読み取りトラフィックを処理したい場合はリードレプリカを使用することが必要です。
実際にダウンタイムやパフォーマンス低下が発生するシーン(障害発生時やメンテナンス、システムアップグレードの実行など)において、フェイルオーバーは有効だと言えます。
自動フェイルオーバーの対象外となるケースやダウンタイムを低減するための注意点などについては、下記の通りです。
- 自動フェイルオーバーは、データベース操作におけるエラー(長時間実行クエリ、デッドロック、データベース破損など)の発生に対しては行われない
- 強制フェイルオーバー時のAZの変更反映は数分かかることがある(コンソール、CLI、API) また、DB インスタンスを再起動するのに要する時間は下記2点に依存する
- データベースエンジンごとのクラッシュ回復プロセス
- データベースアクティビティの量
そのため、データベースアクティビティを減らすことで、未完了のトランザクションロールバックが減り、再起動時間の短縮が期待できます。
フェイルオーバーが使用できないケースも確認しておきましょう。
- available でない DB インスタンス は再起動できない
- データベースは、バックアップが進行中または、以前の要求による変更、メンテナンス時間のアクションなどの理由で使用不可のケースがある
アプリケーションの構成によっては、DNSデータのキャッシュを考慮する必要もあります。
- アプリケーションが DB インスタンス のDNSデータをキャッシュしている場合には、フェイルオーバー後にIPアドレスが切り替わる可能性を考慮する必要がある
- 有効期限 (TTL) の値を 30 秒未満に設定しておくで対応可能
以上です。フェイルオーバーを有効活用して、サービスを安定稼働できるようにしていきましょう。
ご拝読ありがとうございました。

