

S3に入れたファイルをLambdaで解析

今度は実際に、Lambdaの動きを確かめてみましょう。
その前にまずは、Lambdaをどのように使用するかを考えてみます。
Lambdaのトリガー、つまり動くキッカケは、
Dynamo DB、Kinesis、S3が更新されたときです。
小規模であれば、わざわざDynamo DBやKinesisを立ち上げるのは、
あまり現実的ではないと思われます。
なので、Dynamo DBやKinesisとの連動自体のテストでない限り、
基本的にはS3をトリガーとして利用するのがよいでしょう。
S3にファイルをアプロードした時点で、Lambda関数は動作しますが、
同名ファイルで上書きしてもLambdaは動作します。
つまりは、Lambdaを動かすために、無数のファイルを新規作成する必要はなく、
Lambdaトリガー専用のファイルを上書きし続ければいいのです。
こうする事で、S3の領域使用による大きな料金の発生もなく、
更新されるファイルの解析も行えると思われます。
また、Lambda自体も、秒間数千回もの動作が可能なようです。
ただ、その分の料金は発生するかもしれませんが。
まずは、Lambda関数を作成します。
と言っても、ほとんどサンプルのままでも動くとは思いますが、
今回は、必要な情報だけを最小限に取りたいので、
とにかくファイルの中身を取り出す前提に、改造してみました。
var aws = require('aws-sdk');
var s3 = new aws.S3();
exports.handler = function(event, context) {
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
s3.getObject({
Bucket:bucket,
Key:key
},
function(err,data) {
if (err) {
console.log('error getting object ' + key + ' from bucket ' + bucket +
'. Make sure they exist and your bucket is in the same region as this function.');
context.done('error','error getting file'+err);
}
else {
console.log(String(data.Body));
}
}
);
};
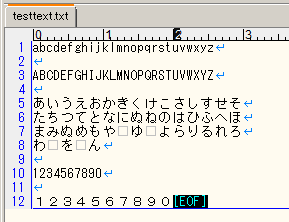
Lambdaを連動させたS3に、以下のようなテキストファイルをアップロードしてみます。
すると、関数一覧のグラフが伸びます。
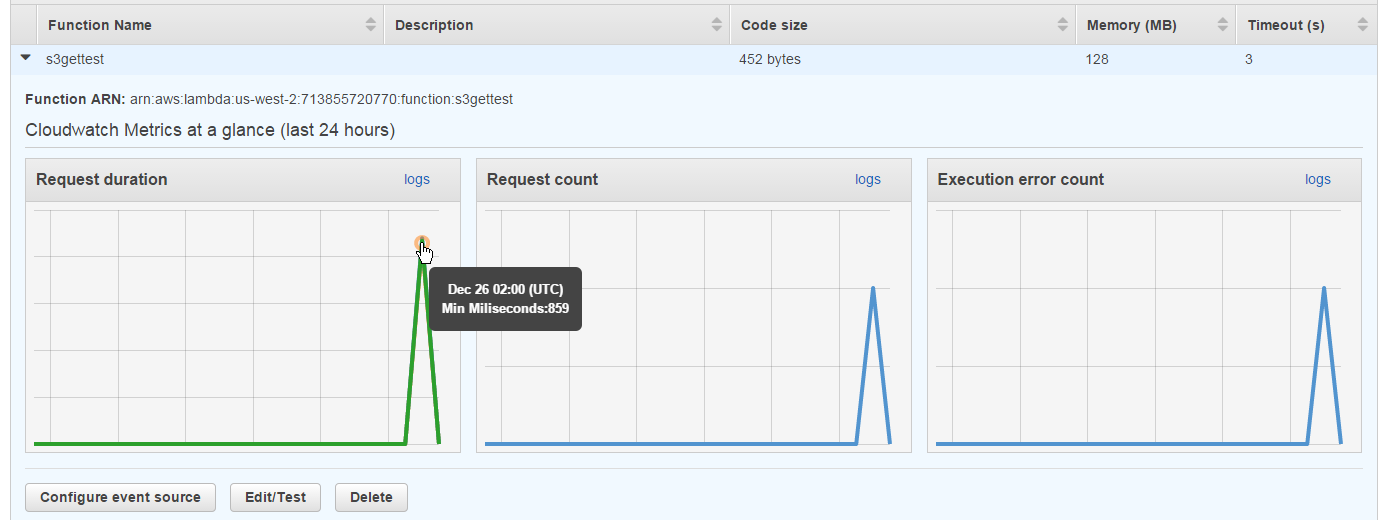
グラフ右上にある青い「logs」の文字をクリックすると、今度はCloudWatchの画面に飛びます。忙しいですね。
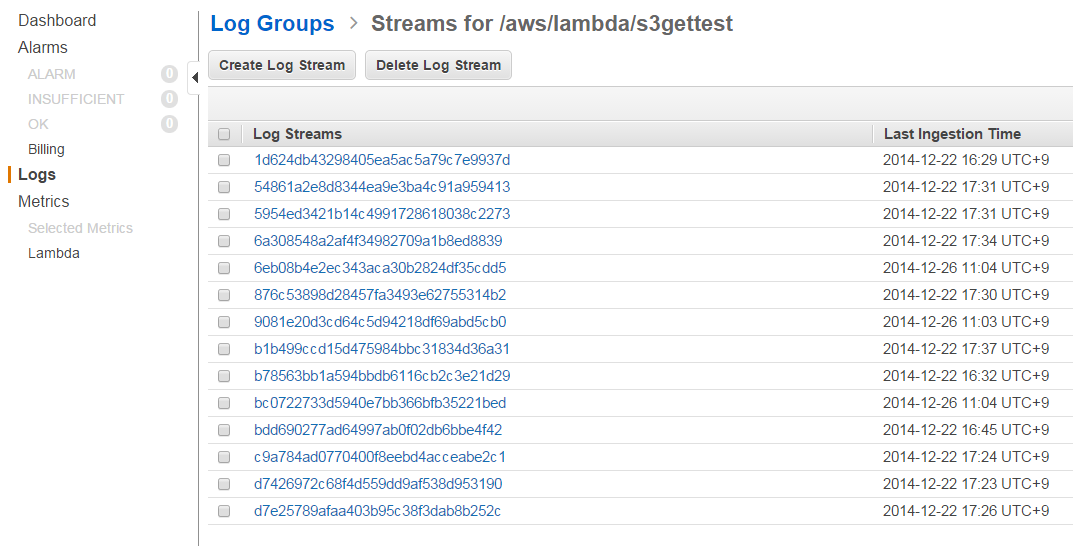
過去に何回かテストしているので、このような雑な状態になっていますが、
この中から、最新のログを探します。
改めてテストをする際には、これらのログは削除しておくとよいでしょう。

ログの中に、テキストファイルの中身がありました。
ここで要注意したいのが、日本語などのマルチバイト文字は、文字化けします。
今回使用したテキストファイルは、UTF-8で保存していたため、幸いにも文字化けしませんでしたが、
実際には、どのような形式のファイルが投入されるかがわからない事前提で、
日本語は確実に文字化けするという意識で運営したほうが、よさそうです。
今度はコードの中身について、説明します。
exports.handler = function(event, context) {
「exports.handler」の「handler」は、
「Change function configuration and role」の「Handler Name」の部分で指定した名称となります。
「Handler Name」で指定した関数名が開始されるという仕組みです。
その中の仮引数「event」に、アップロードしたファイルの情報が格納されていますが、
この時点で、ファイルの中身までは格納されておらず、名前などの表の情報のみとなります。
それは、左ボックスに入っている連想配列サンプルと同じ形式で、各情報を取得可能です。
複数のファイルが一度にアップロードされた場合は、配列の第1層目が追加され、
同じような連想配列が入っているはずです。
それなら、どうやってファイルの中身を取得するのかという事ですが・・・
ファイルの中身取得は、アップロードされた時点で行うのではなく、
一度アップロードされたファイルを読み込んで、ファイルの中身を取得する事になります。
そのためには、AWSのSDKを利用する事になります。
var aws = require('aws-sdk');
var s3 = new aws.S3();
上部にこのような記述がありますが、ここでAWSのお祝いSDKを読み込んでいます。
「var aws = require(‘aws-sdk’);」でSDK本体を読み込み、変数に格納しています。
「var s3 = new aws.S3();」で、さらにS3用SDKに絞って読み込んでいます。
var bucket = event.Records[0].s3.bucket.name; var key = event.Records[0].s3.object.key;
この部分において、アップロードされたファイルの名前と、
アップロード対象のバケット名を取り出しています。
この部分は、SDKからではなく、「event」仮引数内の要素から取り出しています。
s3.getObject({
Bucket:bucket,
Key:key
},(略)
上記の「s3.getObject()」で、SDKを利用して、S3のファイルを取り出す事になります。
第1引数には、対象のバケット名と、ファイル名を連想配列で入力します。
第2引数には、取得したファイルの処理を行うための関数(function)を書いていきます。
関数内の第1仮引数「err」には、エラーが発生した際の情報が吐き出され、
第2仮引数「data」には、取得したファイルの中身を含む情報が格納されています。
関数内では、最初にif文でエラーが出たかどうかで区切っています。
「err」に何も格納されていない場合に成功とみなし、処理する事になります。
おそらくはエラーが発生しなかった場合は、「err」は「null」等の状態なのでしょう。
「data」の中身は、今回はひとまず「data.Body」で中身を取り出してログに表示させています。
その際、String形式にキャストしないと、読める形にうまく取り出せないようです。
これで後は、ファイルの中身に応じた処理を考えていけばいいと思います。
メール送信が可能であればメールで、またはHTTPアクセスにより別のAPIを叩いて、
エラーログから異常などを検知して通知するなどの仕組みを作るのも、いいかもしれないですね。
しかし、わざわざ別サービスを使わなくとも、
そのサーバー内で処理を行ってもいいのではないかと、身も蓋もない事も考えてしまうかもしれませんが、
同じサーバー内で処理を行うと、その分の負荷も考えられますし、
特にt2.microやm1.smallのような、スペックの低めなサーバーの場合、極力過負荷は避けたいものです。
まだまだどのような用途があるかは、わかりませんが、
JavaScriptという、一般的でわかりやすい言語を用いた、将来性や可能性のあるサービスだと思います。
何か思いつき次第、使ってみたいとは思っております。

